
TOC
Update
Story
Janitor
scraper
WebGrep
Alt
Headless
OutilspourMD
Annoter
Linkscheckers
Tunnels
Archive
indexserveur
Textpocessing
via
Update
Dernière version ( 2024 )
https://liens.vincent-bonnefille.fr/?Jxnufg
( dncorpus )
j'ai mis au point un fichier cli_bash
pour GRAV ( grav_wordpress )
qui va chercher les liens dans les pages (sous-dossiers)
- EX/ A => B
puis chercher le fichier/la page en question (liée) ( B )
et indique dans la page ( B ) que ( A ) pointe vers elle - https://gitlab.com/bonnebulle/grav_dn/-/blob/main/user/recursiv_mod.sh?ref_type=heads
Story
Je reprends ma prise de notes avec dendron / Zettelkasten
J'en suis pas à mon premier essai {bulle}
article de référence sur cette méth. de prise de notesJe veux automatiser la mise en prod / publication
Je veux ajouter quelques fonctions "de base" qui font d'un (b)log un jardin...
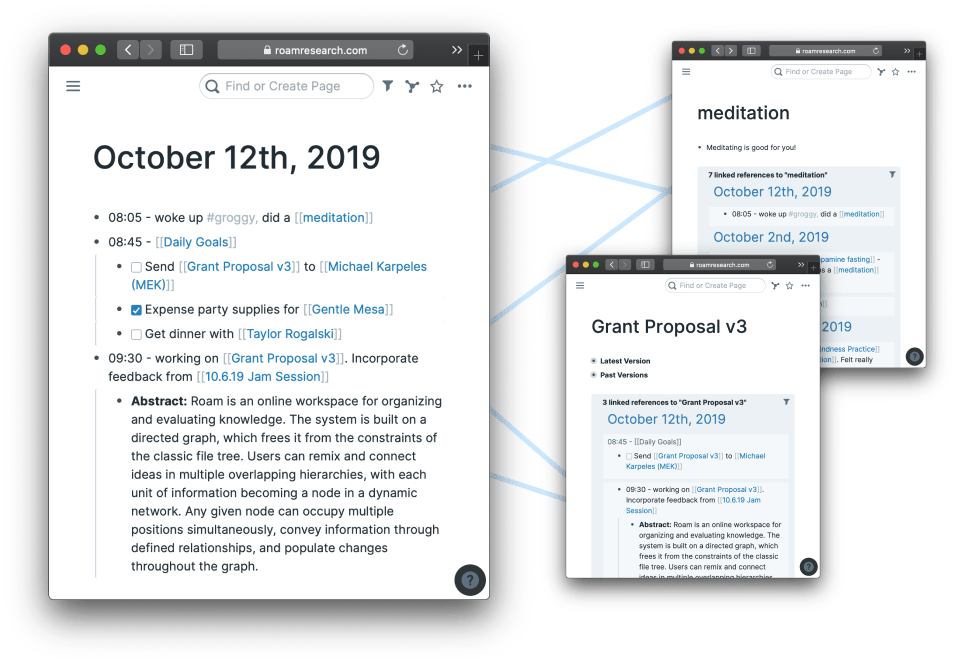
... tel les /Backlinks/ (liens entre articles.notes connexes)
... ce que propose {cet article.lien.bulle}
--> https://sebastiandedeyne.com/adding-backlinks-to-a-github-wiki/
... avec le script /Janitor/Backlinks, or bi-directional links, are becoming table-stakes for productivity apps since they’ve been popularized by Roam. It’s a simple …
{kind=link}
Janitor
-
https://github.com/andymatuschak/note-link-janitor
-> forks https://www.npmjs.com/search?q=note-link-janitor
-> FR : https://www.npmjs.com/package/@arthurperret/note-link-janitor-fr !
Quelques alternatives et autres outils...
pour se balader de liens en liens,
de sites en sites
...
scraper
Un scraper c'est une automatisation de taches programmables permettant de visiter et inte agir avec une page web, sa structure ou des données. On peut ainsi simuler un clic, copier du contenu tel des liens (d'images ou hypertextes), faire une capture écran, etc.
Plusieurs approches...
WebGrep
va chercher du texte à la façon de /grep/
on pourrait ainsi lister les liens
se balader de l'un à lautre...
- https://webgrep.readthedocs.io
- (=) https://github.com/dhondta/webgrep
- (=) https://pypi.org/project/webgrep-tool/
(=/=) des variants
- https://github.com/LLazarek/webgrep
wgrep.py
-u URLS, --urls URLS Regexp for urls to search. By default all urls are searched.
wg (an other)
Alt
Recursive by rounds -R
Spider
Headless
des navigateurs 'sans tête'
on intéragis sans afficher à l'écran la page
on a un accès textuel / via du code
( possible par terminal cli_bash )
- https://github.com/lbarnkow/no_browser
- https://lib.rs/crates/surf
- https://lib.rs/crates/longboard
- https://github.com/http-rs/surf
Je suis aussi tombé sur des outils qui vont me servir dans la création des pages (et leurs interactions par backlinks...
Outils pour MD
toc
tag search <3
like dendron linked notes
Annoter / pdf
extraire annotations pdf -> md <3
Hypothesis direct dans vsc
Search in PDF
pdfgrep
rga
Links checkers
Vérifier la validité des liens
peut être utilile avec le scraper
chker
chker status
Tunnels
Rendre accessible un site en devellopement local
au reste du web en créant un tunel
tunnels
Archive
Sauvegarde, téléchargement de pages
archive / dwl pages
- https://github.com/bcmyers/urls2disk
- https://github.com/mattgathu/duma
- https://lib.rs/crates/shirodl
index_serveur
afichier le contenu d'un dossier
mise en place d'un micro-serveur
j'utilisais http-server
- https://lib.rs/crates/dufs
- https://github.com/http-server-rs/http-server
- https://github.com/svenstaro/miniserve
Text pocessing
-> https://lib.rs/text-processing
via
Via https://sebastiandedeyne.com/adding-backlinks-to-a-github-wiki/