Nouvelle chat_chouquette !
Cette fois j'ai un peu automatisé les choses...
Grâce à https://icrawler.readthedocs.io/en/latest/
J'ai aussi retrouvé ce/cette chouette outil / œuvre
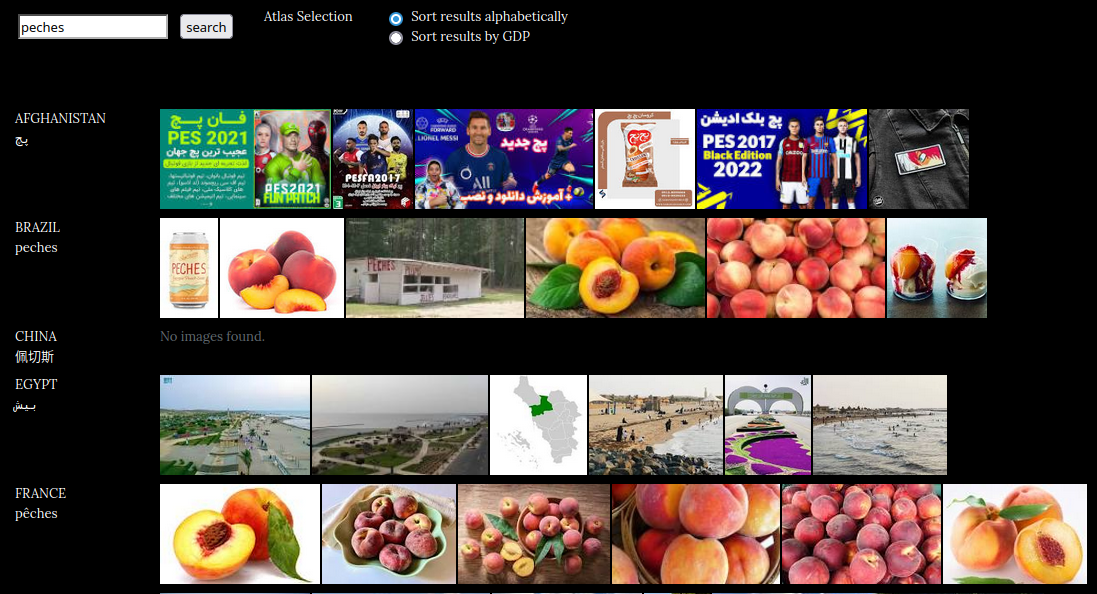
image-atlas
- https://nt2.uqam.ca/fiches/image-atlas
- https://imageatlas.org/search?countries=AF%2CBR%2CCN%2CEG%2CFR%2CDE%2CIN%2CIR%2CIL%2CNZ%2CKP%2CRU%2CSA%2CKR%2CES%2CSE%2CSY%2CUA%2CUS%2CGB&q=peches
Je repense également à

L'image comme répétition... la répétition faisant continuité... la continuité animant l'image
Je pourrais aussi citer @Ellie_Wyatt autour du paranormal

../ pointer des truxs
https://liens.vincent-bonnefille.fr/?bWkaUg

TOC
Update
Story
Janitor
scraper
WebGrep
Alt
Headless
OutilspourMD
Annoter
Linkscheckers
Tunnels
Archive
indexserveur
Textpocessing
via
Update
Dernière version ( 2024 )
https://liens.vincent-bonnefille.fr/?Jxnufg
( dncorpus )
j'ai mis au point un fichier cli_bash
pour GRAV ( grav_wordpress )
qui va chercher les liens dans les pages (sous-dossiers)
- EX/ A => B
puis chercher le fichier/la page en question (liée) ( B )
et indique dans la page ( B ) que ( A ) pointe vers elle - https://gitlab.com/bonnebulle/grav_dn/-/blob/main/user/recursiv_mod.sh?ref_type=heads
Story
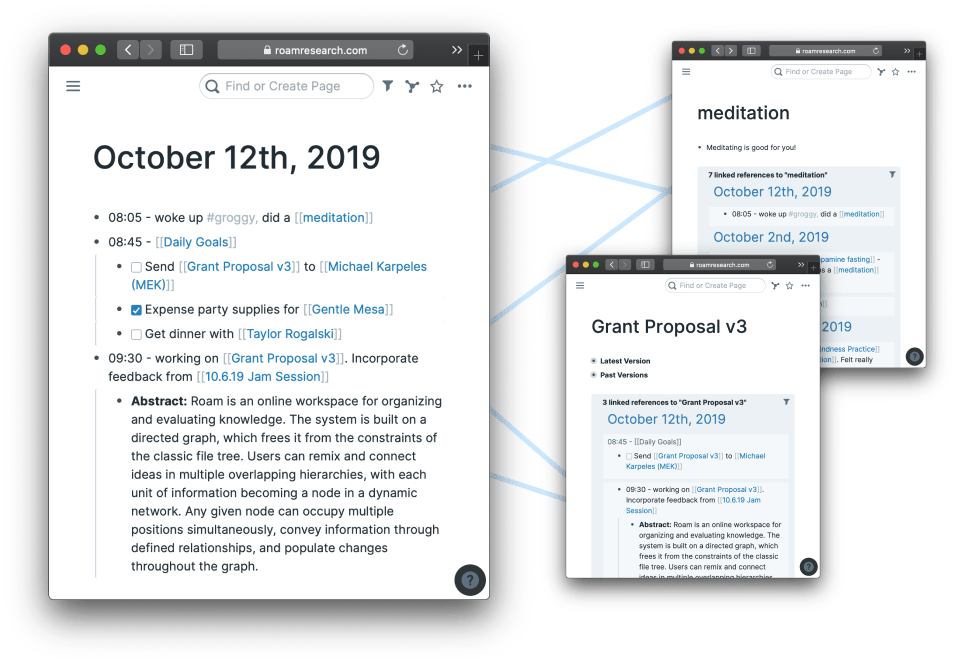
Je reprends ma prise de notes avec dendron / Zettelkasten
J'en suis pas à mon premier essai {bulle}
article de référence sur cette méth. de prise de notesJe veux automatiser la mise en prod / publication
Je veux ajouter quelques fonctions "de base" qui font d'un (b)log un jardin...
... tel les /Backlinks/ (liens entre articles.notes connexes)
... ce que propose {cet article.lien.bulle}
--> https://sebastiandedeyne.com/adding-backlinks-to-a-github-wiki/
... avec le script /Janitor/Backlinks, or bi-directional links, are becoming table-stakes for productivity apps since they’ve been popularized by Roam. It’s a simple …
Janitor
-
https://github.com/andymatuschak/note-link-janitor
-> forks https://www.npmjs.com/search?q=note-link-janitor
-> FR : https://www.npmjs.com/package/@arthurperret/note-link-janitor-fr !
Quelques alternatives et autres outils...
pour se balader de liens en liens,
de sites en sites
...
scraper
Un scraper c'est une automatisation de taches programmables permettant de visiter et inte agir avec une page web, sa structure ou des données. On peut ainsi simuler un clic, copier du contenu tel des liens (d'images ou hypertextes), faire une capture écran, etc.
Plusieurs approches...
WebGrep
va chercher du texte à la façon de /grep/
on pourrait ainsi lister les liens
se balader de l'un à lautre...
- https://webgrep.readthedocs.io
- (=) https://github.com/dhondta/webgrep
- (=) https://pypi.org/project/webgrep-tool/
(=/=) des variants
- https://github.com/LLazarek/webgrep
wgrep.py
-u URLS, --urls URLS Regexp for urls to search. By default all urls are searched.
wg (an other)
Alt
Recursive by rounds -R
Spider
Headless
des navigateurs 'sans tête'
on intéragis sans afficher à l'écran la page
on a un accès textuel / via du code
( possible par terminal cli_bash )
- https://github.com/lbarnkow/no_browser
- https://lib.rs/crates/surf
- https://lib.rs/crates/longboard
- https://github.com/http-rs/surf
Je suis aussi tombé sur des outils qui vont me servir dans la création des pages (et leurs interactions par backlinks...
Outils pour MD
toc
tag search <3
like dendron linked notes
Annoter / pdf
extraire annotations pdf -> md <3
Hypothesis direct dans vsc
Search in PDF
pdfgrep
rga
Links checkers
Vérifier la validité des liens
peut être utilile avec le scraper
chker
chker status
Tunnels
Rendre accessible un site en devellopement local
au reste du web en créant un tunel
tunnels
Archive
Sauvegarde, téléchargement de pages
archive / dwl pages
- https://github.com/bcmyers/urls2disk
- https://github.com/mattgathu/duma
- https://lib.rs/crates/shirodl
index_serveur
afichier le contenu d'un dossier
mise en place d'un micro-serveur
j'utilisais http-server
- https://lib.rs/crates/dufs
- https://github.com/http-server-rs/http-server
- https://github.com/svenstaro/miniserve
Text pocessing
-> https://lib.rs/text-processing
via

Petite MàJ de mon outil de capture de sites web
( utilisé { ici } pour faire les aperçus )
-> Page entière ( HD )
-> Crop d'image ( rognée )
-> Thumbnail ( image d'aperçu poids réduit : gif )
MAJ des captures par URL -> base 32 )
MAJ index des captures par URL
Le cheminement, {bulle} d'intro
https://liens.vincent-bonnefille.fr/?NYPb2w
Ex ( HD non cropée )

Cet outil me sert { ici, sur shaarli } et dans ma veille pour créer des aperçus de pages web.
Des captures écran (ou "instantanés") qui sont ensuite redimensionnées (thumbnails)
Me sert (et peut servir) : pour de la sauvegarde / archive :: archéologie_num .
Mises à jour . ajouts
MAJ : ajout de détection des liens vidéo Youtube / Invidious 2021
MAJ : ajout d'une sauvegarde de 5 versions (par URL-page)
MAJ : ajout d'une version datée-titrée (incorporé à l'image)
MAJ : ajout de conversion img.jpg (+ base64) 2022
MAJ : gestion des accents, dé/en.codage (partiellement)
MAJ : ajout d'un lien incitatif de YT vers #.invidious
MAJ : gestion pour img.jpg, conv. selon dimensions
MAJ : fullpage + crop + thumb
https://liens.vincent-bonnefille.fr/?l3HsUg
Outils . fonctionnement
Mon serveur utilise nodejs avec Puppeteer ( bot_scraper )
Pour éviter Chrome j'ai aussi essayé cutycapt
Je me suis inspiré de https://addons.mozilla.org/fr/firefox/addon/searchpreview/ ...
Limites
J'ai observé pas mal de modules se rapportant à /Puppeteer/ étaient liés à /PhantomJS/ ( dont le dev. est en pause et surtout l'installation sur Raspberrypi un poil unofficial (bidouille, build manuel...) pas top en matière de durée_de_vie ...
Du coup j'ai repris une mini étude de marché des logiciels de "scrapping" permettant d'explorer le web bot .... et je suis retombé sur : https://scrapy.org #<3 ( capture plus bas ) ... que j'avais utilisé en 2017 pour explorer le Darknet Tor... Du coup c'est une nouvelle piste, un autre angle d'attaque-recherche.
Résultats avec {cet} "outil maison"


! Awsome list alternativeto
https://github.com/duyet/awesome-web-scraper
ArchiveBox (alternative)
(prêt à l'emploi) (un archive.org auto-hébergé/local)
Pour une offre prête à l'emploi (avec même une version application -avec Electron-) vous pouvez utiliser ArchiveBox https://liens.vincent-bonnefille.fr/?VvYV3w ...
Moi je l'utilise à nouveau pour de la sauvegarde de sites web
(ça crée une archive Warc / html avec ressources / pdf / capture partielle / ...)
Archivebox + Pupet
-
Add ability to run JS scripts during archiving with Playwright/Puppeteer
https://github.com/ArchiveBox/ArchiveBox/issues/51
( cacher modals / popups / cookies ) -
Autoscroll before before archiving and take full-height screenshots
https://github.com/ArchiveBox/ArchiveBox/issues/80
Aller plus loin (notes pupet)
Pistes plein écran ( auto scroll sur la hauteur )
https://blog.rasterwise.com/Puppeteer-Screenshot-Full-Page-Not-Working-Possible-Fixes-and-Alternatives
https://docs.browserless.io/blog/2018/02/22/large-images.html
https://www.titanwolf.org/Network/q/5c0608d1-34ae-4c37-ae1d-2192cbbc1cd0/y
https://zxc0328.github.io/2018/02/12/hdchrome-long-capture/

@Darknet_Diaries ( podcast )
https://darknetdiaries.com/episode/13/
https://darknetdiaries.com/transcript/13/ hypothesis
https://liens.vincent-bonnefille.fr/?cVx5Bw
"While playing around with the Nmap Scripting Engine_ (NSE) we discovered an amazing number of open embedded devices on the Internet. Many of them are based on Linux and allow login to standard BusyBox with empty or default credentials. We used these devices to build a distributed port scanner to scan all IPv4 addresses. These scans include service probes for the most common ports, ICMP ping, reverse DNS and SYN scans. We analyzed some of the data to get an estimation of the IP address usage.
All data gathered during our research is released into the public domain for further study. "
2012
-
Carte interactive
http://census2012.sourceforge.net/hilbert/index.html -
Paper (intro)
https://census2012.sourceforge.net/paper.html -
paper (étude)
https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=ccc3f8ae7e9bdfadc98d17b731e3a85f2c4834bb -
archive :
https://web.archive.org/web/20180216031145/http://census2012.sourceforge.net/paper.html
Adresses IP
( et masques de sous-réseau )
-
https://www.frameip.com/masques-de-sous-reseau/ hypothesis
Une adresse IP divisée en 2 parties
cest le masque de sous réseau qui rend distinct les 2)
la première (avec des bit 1 => contient le réseau)
la seconde (avec des bit 0 => id unique d'une machine sur ce réseau)l’adresse IP est une suite de 4 octets, soit 32 bits. Chacun des ces bits peut prendre la valeur 1 ou 0. Et bien il nous suffit de dire que les bits à 1 représenteront la partie réseau de l’adresse, et les bits à 0 la partie machine
-
https://fr.wikipedia.org/wiki/Octet hypothesis
En informatique, un octet est un multiplet de 8 bits codant une information1. Dans ce système de codage s'appuyant sur le système binaire, un octet permet de représenter 2^8 (2puissance8) nombres, soit 256 valeurs différentes.
IP 0.0.0.0 -> 255.255.255.255
-
htps://www.frameip.com/masques-de-sous-reseau/
Calcul nombre total :
En y regardant d’un peu plus près, on peut calculer le nombre de machines que l’on peut identifier à l’aide de cet adressage. Ainsi, on utilise 4 octets, soit 32 bits, soit encore 2^32 adresses (2 exposant 32 adresses) Or 2^32 = 4 294 967 296, on peut donc définir un peu plus de 4 milliards d’adresses !!!
-
CAIRN (leur attribution)
https://fr.wikipedia.org/wiki/Internet_Corporation_for_Assigned_Names_and_Numbers
Story
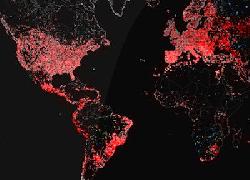
(1) Chercheurs en sécurité trouvent qu'un grand nombre de machines ont le port Telnet ouvert
(1a) Nmap : https://www.kali.org/tools/nmap/
(1b) qu'ils sont peu sécurésés avec un pwd par défaut
(2) Ils décident de répliquer à grande échelle l'experience ( illégale )
=> Augmenter le nombre de ces machines
( = les hacker ==> pouvoir y installer d'autres logiciels que ceux du constructeur )
(3) Ils se rendent compte du grand nombre de machines = 40000+
( 420,000 systems )
(3b) Ils auraient pu en faire une armée de bot => attaque DDOS
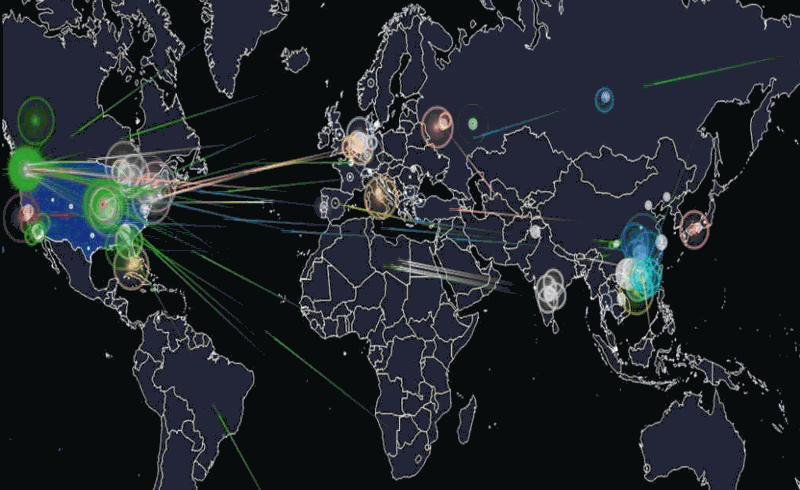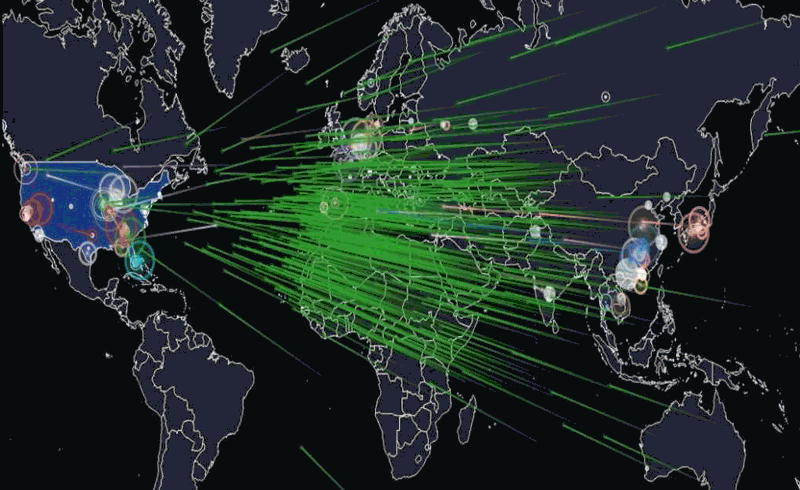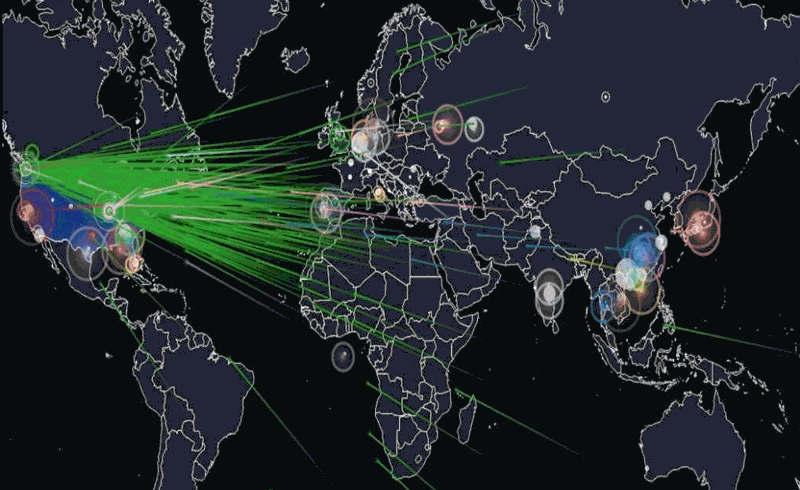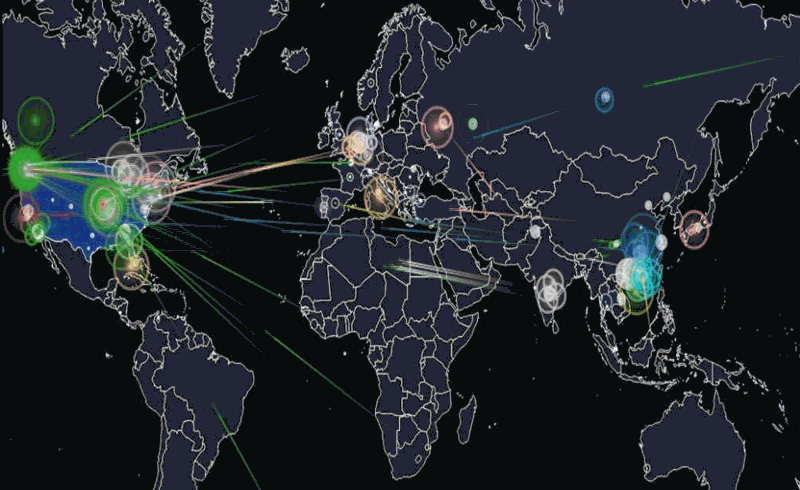
(4) Ils décident d'utiliser ce super pouvoir pour :
(4a) - faire une photographie du réseau
càd - de toutes les connexions IP qui répondent au pings
//// un projet a grande échelle avec une lourde logistique + adaptabilité
///// + éthique , ils décident de ne pas s'attaquer à certaines infra
///// + d'user un minimum d'énergie
==> de sauvegarder ces données
==> ( 3.6 billion==milliard IPs )
(4b) de débusquer un virus ( Aidra ) présent sur "leurs" machines
== Aidra 30,000 /sur les/ 420,000 Cara
+ prévenir les usagers des routeurs mal sécurisés
(4c) d'en faire la spatialité / map / visualisation
. . .
ÉTUDE COMPLETE 2018
? pourquoi Hilbert Curve
-
https://blog.benjojo.co.uk/post/scan-ping-the-internet-hilbert-curve
? passer entre toutes les plages d'IP ( masques de sous-réseaux )
: Courbe de remplissage
fr : https://fr.wikipedia.org/wiki/Courbe_remplissante
eng : https://en.wikipedia.org/wiki/Space-filling_curve
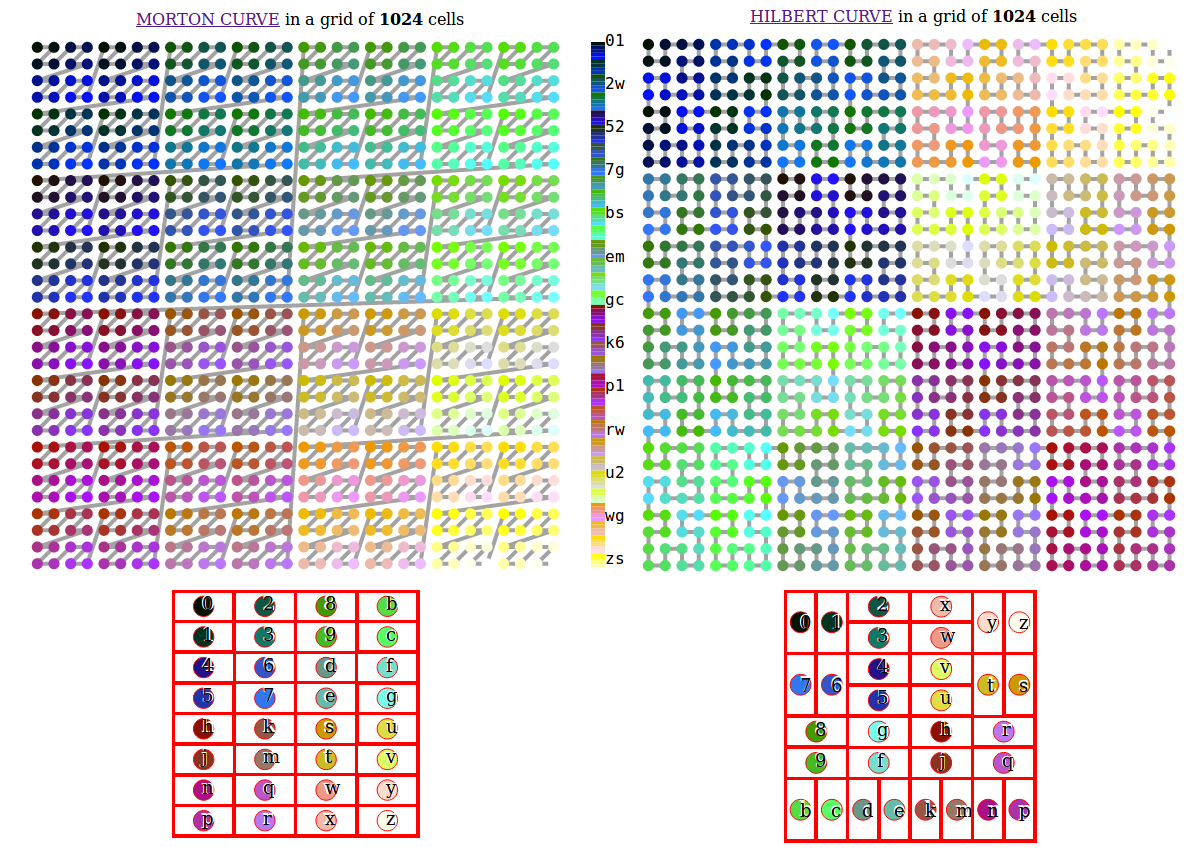
-
https://blog.benjojo.co.uk/asset/OHMMBrt565
-> git tool https://github.com/measurement-factory/ipv4-heatmap
( APNIC : https://fr.wikipedia.org/wiki/Asia-Pacific_Network_Information_Center )
TLD
- git Carabot TLDs
https://github.com/decal/werdlists/blob/master/dns-toplevel/carna-botnet-tlds.txt - .apple
https://icannwiki.org/.apple
Articles ( hypothesis )
- DarknetDiaries ( podcast )
https://darknetdiaries.com/transcript/13/ hypothesis - Researcher sets up illegal 420,000 node botnet for IPv4 internet map • The Register
https://www.theregister.com/2013/03/19/carna_botnet_ipv4_internet_map/ - Hacker Measures the Internet Illegally with Carna Botnet - DER SPIEGEL
https://www.spiegel.de/international/world/hacker-measures-the-internet-illegally-with-carna-botnet-a-890413.html
WHOIS MAPS
- Internet Identifier Consumption (IIC) - CAIDA
https://www.caida.org/archive/id-consumption/ - IPv4 Census Map - CAIDA
https://www.caida.org/archive/id-consumption/census-map/
COMICS
-
https://xkcd.com/195/ (map and grass not used parts)

-
https://xkcd.com/865/ ( nano bots en manque d'IP(v4) )

- 865: Nanobots - explain xkcd
https://www.explainxkcd.com/wiki/index.php/865:_Nanobots - 802: Online Communities 2 - explain xkcd
https://www.explainxkcd.com/wiki/index.php/802:_Online_Communities_2 - 195: Map of the Internet - explain xkcd map_carte GAFAM
https://www.explainxkcd.com/wiki/index.php/195:_Map_of_the_Internet
Breaches / Vulnerabilities
- https://www.shodan.io
- https://informationisbeautiful.net/visualizations/worlds-biggest-data-breaches-hacks/
@Nicolas_Maigret avait produit une carte de la distance entre les points/villes du monde
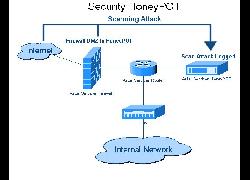
"Dans le jargon de la sécurité informatique, un honeypot est une méthode de défense active qui consiste à attirer, sur des ressources, des adversaires déclarés ou potentiels afin de les identifier et éventuellement de les neutraliser."
Projet de lutte contre le spam
https://www.projecthoneypot.org/
HP en français, leur fonctionnement, les stratégies, quelques tutos ressources
http://igm.univ-mlv.fr/~dr/XPOSE2009/botnets/honeypot.html
Liste d'HP en anglais
https://github.com/paralax/awesome-honeypots
https://www.smokescreen.io/practical-honeypots-a-list-of-open-source-deception-tools-that-detect-threats-for-free/

" This video looks at one of the most popular projects that //!Mediengruppe_Bitnik has worked on with bots, the Random_Darknet_Shopper. The project investigates how these autonomous systems work within a network that offers anonymity. "
Site du projet
https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/r/
2014 2015 2016
CONF
Opera Calling / Delivery for Mr. Assange / Random Darknet Shopper
- https://vimeo.com/157831003
Delivery for Mr. Assange
=> https://liens.vincent-bonnefille.fr/?CqrZGQ
[ 01:50 ] Bot is crashing a lot => live desktop test
[ 41:50 ] Black --> Equador packet opening
BOOK / PUB
- https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/book/
- https://www.liberation.fr/culture/2015/01/19/le-random-darknet-shopper-un-robot-derriere-les-barreaux_1183963/
- https://aksioma.org/jon-lackman-random-darknet-shopper
- https://www.mastersandservers.org/projects/mediengruppe-bitnik-random-darknet-shopper/
- https://bib.vincent-bonnefille.fr/book/80
Expo / Buys
- The Lord of the Rings Collection
https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/r/004-lord-of-the-rings/ - Exhibition View - Kunst Halle St. Gallen
https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/r/kunsthalle-sg/ - Swiss Public Prosecutor seizes and seals work by !Mediengruppe Bitnik
https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/r/2015-01-15-statement/ - Ecstasy is Ecstasy
https://wwwwwwwwwwwwwwwwwwwwww.bitnik.org/r/2015-03-04-xtc-is-xtc/
Artists

"Robot" achetant aléatoirement des produits proposés sur le catalogue d'une plateforme d'achat-vente sur Internet via un protocole d'échange sécurisant et anonymisant son origine (( le tout à l'aide d'une crypto-monnaie décentralisée des banques-États )).

Original website http://www.no-home-like-place.com [DEAD]
--> Git https://nonlinearnarrative.github.io/no-home-like-place/
Airbnb is a global hotel filled with the same recurring items. Bed, chair, potted plant, all catered to our cosmopolitan sensibilities. We end up in a place that's completely interchangeable; a room is a room is a room.
An algorithm finds these recurring items and replaces them with the same items from other listings. By clicking them, you can jump between rooms and explore the global hotel. There are many homelike places.
Open-source
You can find the source code for the various tools we created and used to make this website on Github.
Workshop
Outcome of a week-long web scraping workshop led by Jonathan Puckey at Non-Linear Narrative, a masters programme at the Royal Academy of Art The Hague. "
GIT : https://github.com/nonlinearnarrative/no-home-like-place
GIT : https://github.com/nonlinearnarrative/scrape-airbnb ( scrape-airbnb )
Cours : Master @Non_Linear_Narrative :
https://www.kabk.nl/en/programmes/master/non-linear-narrative
( @Royal_academy_of_art_the_hague )
" Led by @Jonathan_Puckey " :
https://puckey.studio UX
( où il relate des projets aussi fun que pointer-pointer [Bulle] )
Je l'ai aussi retrouvé ici https://work.bnjmnearl.eu/projects/no-home-like-place/
( un site d'artiste web.créatif ... avec plein de projets fun )
Étrange de redécouvrir cet appartement infini en cette ère du covid
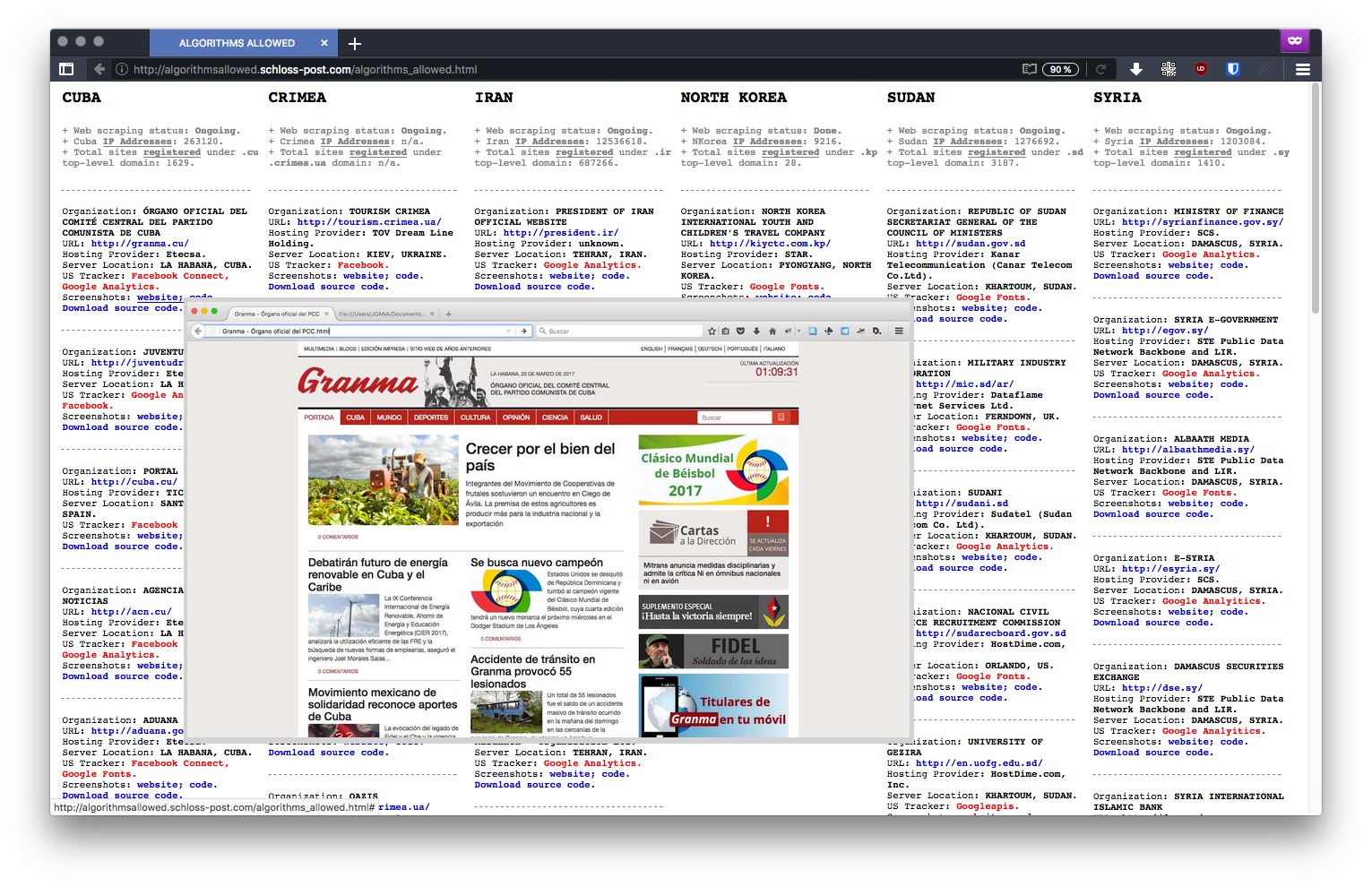
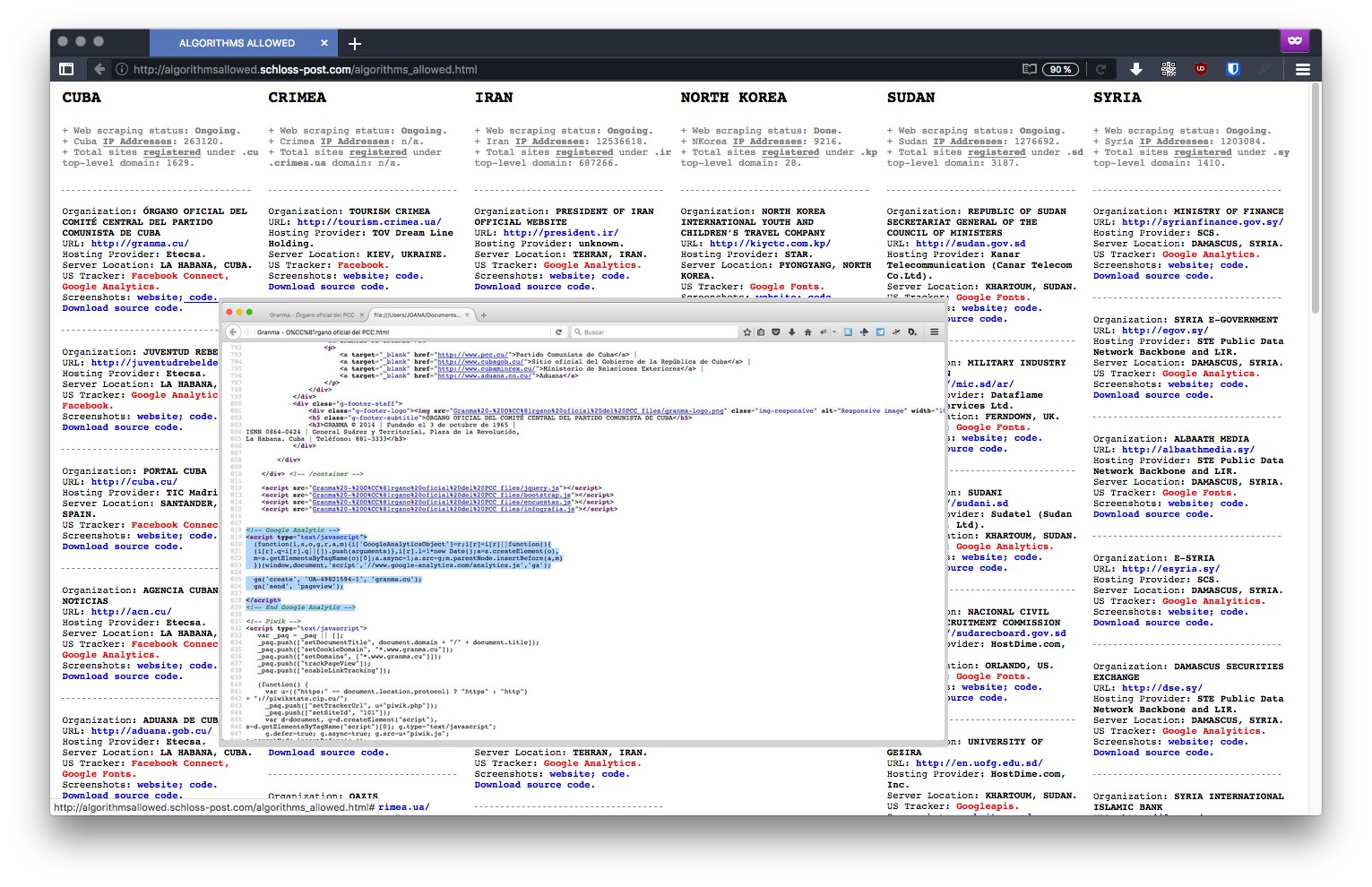
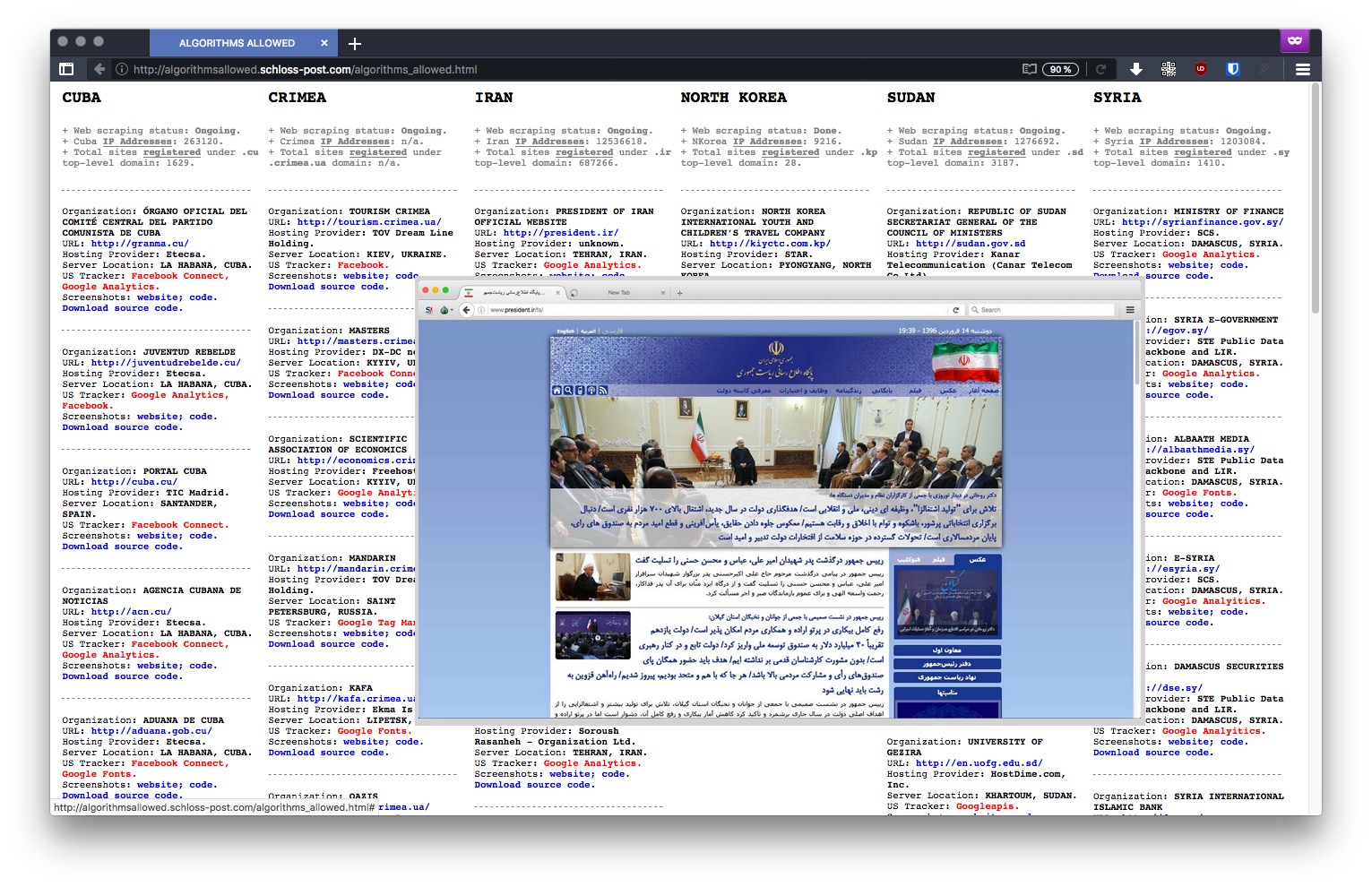
"The IP.Spy.Sequencer is the first application made for the Antidatamining project. It visualizes the activity of a particular network, whose center has been defined as the RYBN main website. This application was made using the data-monitoring and digital surveillance tools - Traceroute, Whois and Lookup
The application recovers the website's homepage login related informations : IP addresses, previous site or entering links, login time and date, Operating System, browser, downloaded bytes, access paths... All these informations are recorded into a database. In a second time, the data are crossed with a GeoIP database, allowing to determine the visitors geographical location."

A project by @Joana_Moll
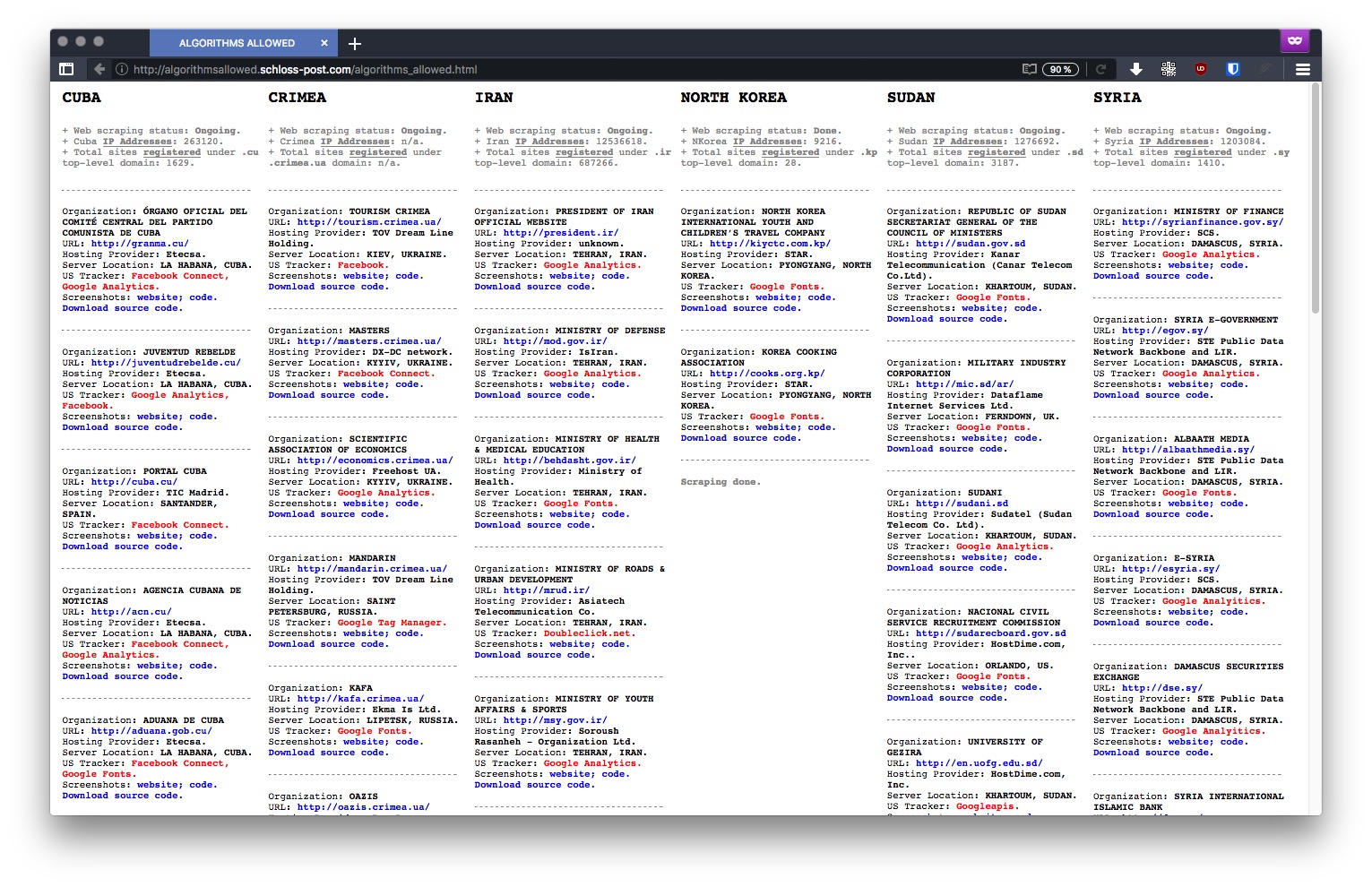
" Typically, a tracker is a piece of code placed within a particular website that allows to monitor and collect data on user behavior. For instance: a tracker can automatically know where a user is based, which computer they’re using, which sites have been visited before accessing a particular site, and which webpages will be accessed in the future – among other more detailed and personal information. The US is currently enforcing embargoes and sanctions against Cuba, Iran, North Korea, Sudan, Syria, and the Ukrainian region of Crimea. "
" This project has been developed as part of the web residency program — Blowing the Whistle, Questioning Evidence - curated by Tatiana Bazichelli for Solitude & ZKM. "
Web résidence du ZKM
J'aime beaucoup ce projet,
la mise en valeur des données, le scraping avec tor
- Crée de la confusion à l'endroit de la propriété des données et de l'information
à l'endroit des États représenté en ligne www - Ils ont en communs d'avoir leur code "occupé" par Google, en "sortant"
- Cela pose des questions de gouvernance #.p
quotes ( homepage project )
" a tracker can automatically know where a user is based, which computer they’re using, which sites have been visited before accessing a particular site "
" American IT giant, have been found within several websites owned by countries under US embargo "
" US is currently enforcing embargoes and sanctions against Cuba, Iran, North Korea, Sudan, Syria, and the Ukrainian region of Crimea "
" It is important to remember that these websites are stored inside hard disks placed in physical territories "
" "ALGORITHMS ALLOWED" unfolds as an ongoing investigation that reveals the many US tracking and online services embedded in websites representing US embargoed countries, thereby exposing the ambiguous relationship between code, public policy, geopolitics, economics, and power in the age of algorithmic governance. "

Google Captchas
Spying and detect false humains
How to ? It's secret for good...

J'aime beaucoup ce que nous raconte les artistes dans cette vidéo
Elle révelle surtout la géométrie variable avec laquelle les "Darknets" sont traité... ou plutôt le principe de l' obfu_secret fondamental aux banques et super-marchés connectés.
De tous ces espaces fermés, heureusement secrtes-privés...
ces réseaux réservés qui appartienet au DeepWeb parcequ'effectivement on ne peut les indexer, en tirer des données (au moins de la part de la concurence et certains bot_scraper ( on omet un peu vite les traitements de données internes aux entreprises qui voudraient faire fructifier les données dormantes ou darkdatas... ). Mais oui, en effet le bot de Gogle ne va pas où il veut et c'est bien comme ça.
Bon bin des fois l'errreurrr est humaine et les portes s'ouvrent...

Que se passe t il quand on laisse les clefs de son compte banquaire à Internet ?
Quand on fait de cet espace symboliquement le plus privé et sécurisé, un espace de intrusion_vulnérabilité volontaire ? Un espace_public dans le cyber_espace ? C'est ce que nous racontent ces deux artistes.
@Ferenc_Gróf and @Jean-Baptiste_Naudy
installation pour les RIAM 06 à Marseille en 2009
http://www.riam.info/06/indexb379.html
alt.vidéo : https://www.youtube.com/watch?v=qF1qPgM-WUo
( leur site est .dead http://www.societerealiste.net )
{kind=link}
"In 2012 the Carna botnet was built and unleashed on the world. But it didn’t have any intentions on doing anything malicious. It was built just to help us all understand the Internet better. This botnet used the oldest security vulnerability in the book. And the data that came out of it was amazing.
The Carna botnet was used to scan the internet to create a map of where all the public facing computer are in the world. The map it created is remarkable."